I have good news and bad news regarding a replacement. The good news is that there has been a replacement in plain sight for several years now. The bad news is that it’s not a one to one replacement. But that’s not a totally bad thing.
Background
palette_generator mirrors the Android Palette API that is pretty ancient in Android terms. The initial Android support library dates back to at least 2017. Back then, Material was only a couple years old (it just turned 10!), and public release numbers for Android were still in the single digits. Eventually, that version of the API was locked as stable in 2018.
While that library has been etched in stone, the ways we use and define color for theming have continued to evolve. I wrote a post almost a year ago detailing how to think about color in Material 3. I won’t rehash it here other than to say that the relationships between color roles are well considered in Material 3. The output of the Palette API/palette_generator wouldn’t work well in a Material theme and would likely still be limiting in a more bespoke Flutter theme.
This limited set of tones (Vibrant, Vibrant Dark, Vibrant Light, Muted, Muted Dark, Muted Light) doesn’t have affordances for contrast levels or for generating complementary colors. It simply takes the dominant colors in the image and tries to slot them into one of those roles.
What to Use Instead?
So if the palette_generator package and the Palette API is not a good solution, what should you use instead, you might be wondering. material_color_utilities is the answer. It’s bundled as a dependency of Flutter, so it’s highly available across implementations. But what if you aren’t using Material? You can still use it; you can determine how "Material-y" you want to be.
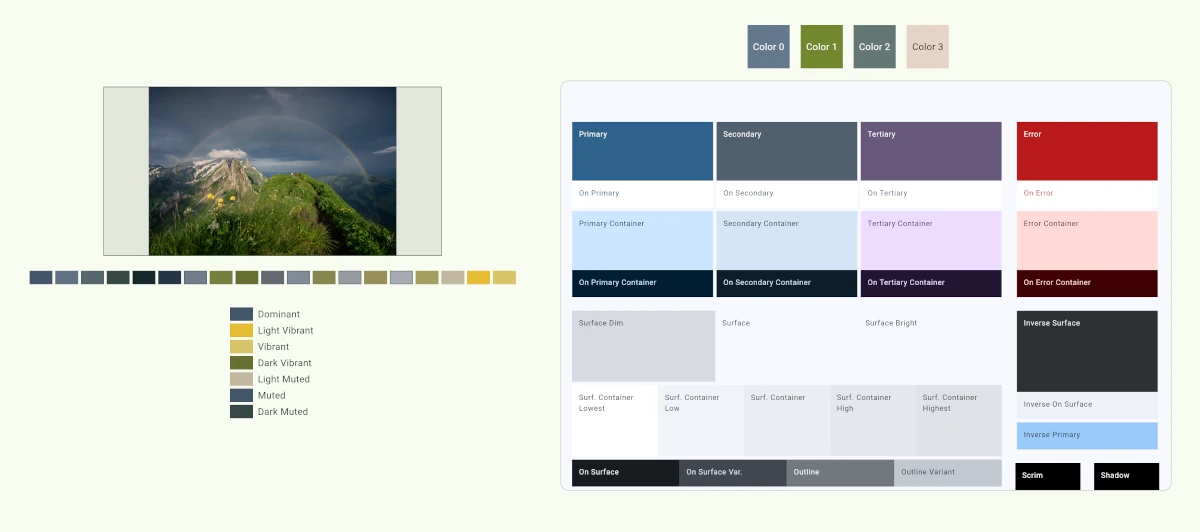
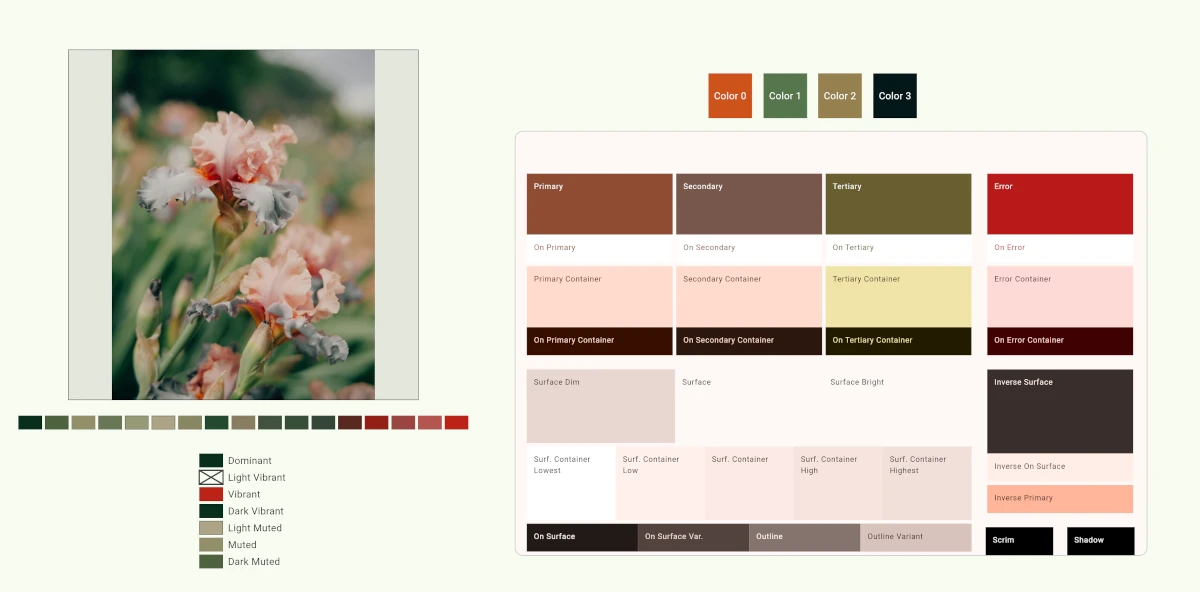
If you just want the colors, use the function getColorsFromImage. The scoring algorithm will run some out as being unsuitable for a UI but it doesn’t mutate the colors. If no suitable colors are found, material_color_utilities will return blue or red (though that is an increasingly rare error condition).
You can pass any of the returned colors into ColorScheme.fromSeed() to generate a full scheme (with a shifted version of that color in the primary slot). If you want that literal color, you can call ColorScheme.fromSeed with a dynamicSchemeVariant parameter set to DynamicSchemeVariant.fidelity or DynamicSchemeVariant.content.
In the screenshots below, we can see another reason why the older API is not reliable; sometimes not all of the color roles are populated.
This is just one of the useful capabilities of material_color_utilities and related classes like ColorScheme. Flutter developers can implement more sophisticated and flexible color extraction in their apps, align with modern design principles, and choose how much they want to adhere to a specific design system.
It’s the starting of December so that means devs from all over the world gather to solve Christmas-based programming problems for the Advent of Code. Some come to sharpen skills in their main programming language, others use it to learn a new language, or as I did in years past, as preparation for tech interviews. Over the month the difficulty ramps up to thin out the herd, not unlike visiting the gym on Jan 1 vs Jan 30. Even if you don’t rush to complete the problems as fast as you can, it’s a useful exercise to look at other folks' solutions. You will probably learn about a new API or two.
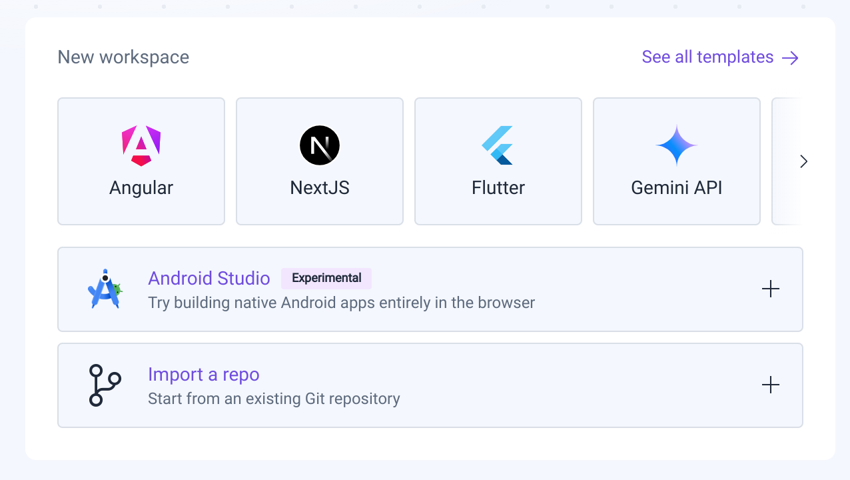
Testing out Project IDX
I decided to use this year’s AOC as a premise to test out Project IDX. It’s a browser based development environment that comes with a bunch of pre-configured workspaces supporting common web frameworks, Flutter projects, and can create a workspace from an arbitrary GitHub repository. There is also experimental support for Android projects. IDX was announced with a waitlist in 2023 but opened up to general availability in May 2024.
The environment is VSCode based so most of your workflows will work with some caveats here and there.
Importing and Running the Project
My repo is mostly Kotlin code and uses Gradle, the build system for most Java, Kotlin, and Android project. This would end up being the cause of my first hiccup in running code. One way I’ll run a gradle-based project on a new machine is to install Java and use the gradle wrapper that’s bundled with a project, which will bootstrap Gradle and all its dependences. That was a bit of a nonstarter because the workspaces are spun up and down as needed and I wasn’t quite sure how to make persistent changes.
On a whim, I decided to try gradle run and see what would happen. IDX tells you gradle is not installed, advises you that can add it the the packages of your dev.nix file, and gives you a choice of which version to run. I thought I’d be able to add it at that moment by clicking OK or that gradle would be temporarily in the workspace until shutdown. It unfortunately wasn’t.
With less than sixty minutes until the first problem would unlock, I was on a frantic search to get the packages built into my workspace to avoid getting the same problems and delays on every run. GitHub projects don’t seem to have a dev.nix file created on import and my repo a bunch of difference programming challenges separated by directory so I didn’t know where exactly to put the file or the proper format. Turns out dev.nix belongs in a top-level .idx directory. With that figured out, it was pretty straight forward to add support for new languages and enable extensions from OpenVSX registry. It’s important to note that IDX deviates from a local VS Code installation. Extensions will install dutifully via the IDE flow and DO NOTHING.
My dev.nix file ended up looking like this:
{ pkgs, ... }: {
# Which nixpkgs channel to use.
channel = "stable-24.05"; # or "unstable"
# Use https://search.nixos.org/packages to find packages
packages = [
pkgs.kotlin
pkgs.kotlin-language-server
pkgs.dart
pkgs.openjdk11
# pkgs.go
# pkgs.python311
# pkgs.python311Packages.pip
# pkgs.nodejs_20
# pkgs.nodePackages.nodemon
pkgs.gradle
pkgs.kotlin-native
];
# Sets environment variables in the workspace
env = {};
idx = {
# Search for the extensions you want on https://open-vsx.org/ and use "publisher.id"
extensions = [
# "vscodevim.vim"
"Dart-Code.dart-code"
"Dart-Code.flutter"
"fwcd.kotlin"
"mathiasfrohlich.kotlin"
];
# Rest of file truncated
}
In the dev environment, a clickable "Add Packages" region appears just above the packages that integrates with the command palette to allow you to search for and add packages.
With a few more edits to the dev.nix file, I was able to get the workspace close to a local VS Code but not quite. Dart code-complete works as expected without much fuss. Kotlin code-complete, usually provided by the kotlin-language-server package, seems to fail somewhat silently because it can’t find JAVA_HOME. Even after adding the openjdp package, there’s no visible error but code complete does nothing after the language server seems to start. Perhaps the needed port is being blocked by defaul. Not a deal breaker for something that sits in the realm of experimental.
(Temporary I Hope) Disadvantages
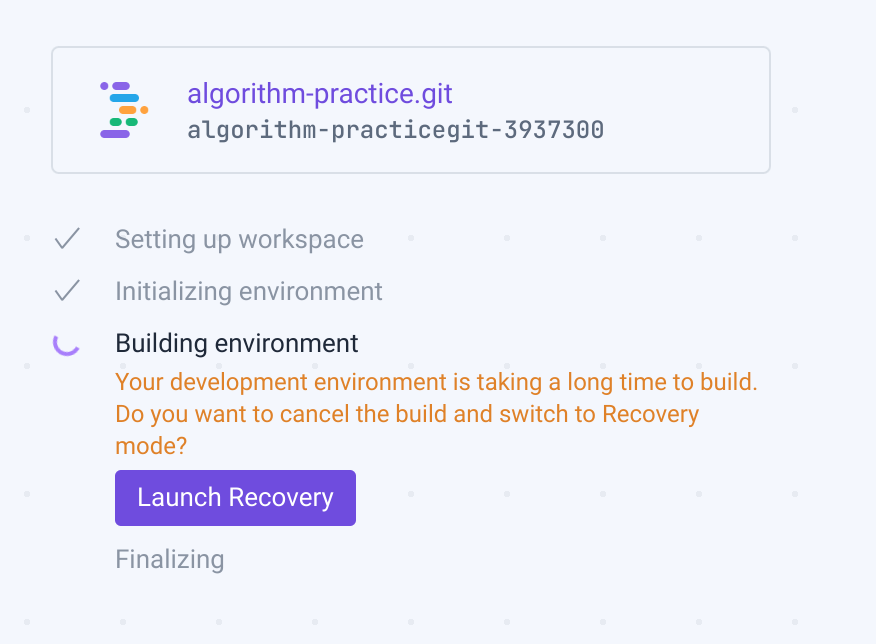
Adding Java related packages to the workspace created a substantial delay in workspace initialization. Dart packages didn’t.
After spinning for a while, I would get a scare message asking if I want to switch to recovery mode. Wait a bit longer and it’s fine. I’ve been starting it up and then getting up to get water/coffee or hit the head.
I’m sure this will be addressed as Android support is worked on.
Takeaways
Having a remote box for dev is something I use in my day job from time to time for some large builds. You can spin up an instance, start a build, and disconnect and it’s still there. Having that remote interface has already helped me during AOC. Working from multiple computers always runs the risk that one side isn’t synced so you get weird merge conflict or have to stash things. I was working on the code on my aging and rather unstable desktop computer. It locked up and crashed during an environment rebuild. I was able to pick up my laptop and continue without having to lose or check-in partially complete work.
It’s quite there for Kotlin and could be helped a bit by creating the config dirs/files when you import a GitHub repo but the caveats haven’t chased me away…yet.
As of Google I/O 2024, it’s been three years that I’ve been talking about Material 3. As the spec has evolved, the way that I teach it has evolved too. For a while, I’ve been mulling a post noting the fundamentals I wish I’d focused on when we first released it. The content that follows is what I think is the best, or at least a good way, to explain Material 3 and its intricacies to designers and devs alike. Thanks to y’all who unknowingly helped me refine it.
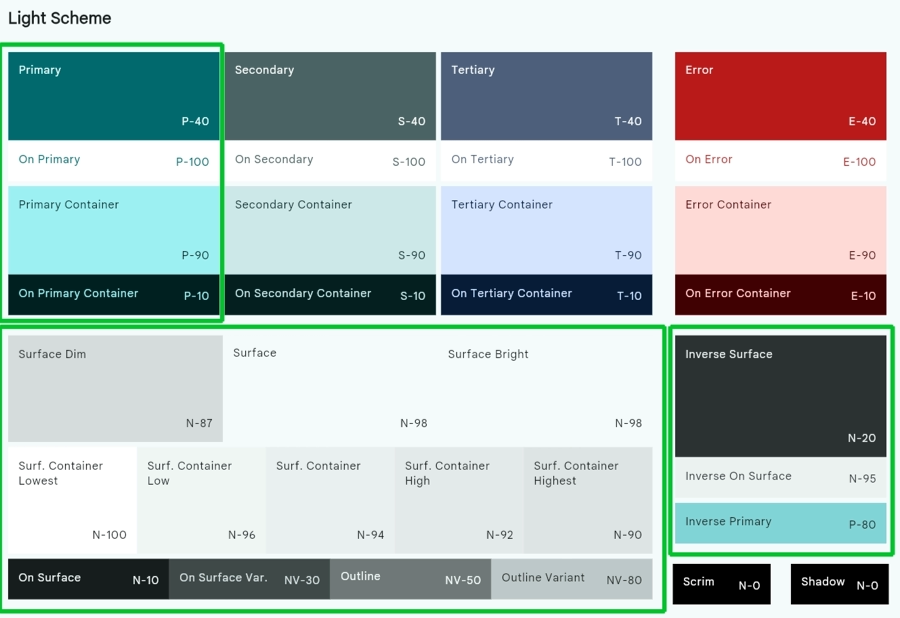
My method sort of banks on a couple of rules that underpin Material 3 as a design system. Don’t click away. Yes, I’m talking about this Material with forty plus colors in a scheme and explaining it with a couple rules. Bear with me.
Light Theme
Dark Theme
The rules
The core concepts I’ve come up with are all interconnected. Each more or less builds on the one before it.
A key color is used to create other colors or derive an entire theme.
For every named color, there is a complementary named color that is guaranteed to have proper contrast when you use the two together.
A color family is a set of colors related to a key color providing variety and required contrast. Color families are two or more iterations of the preceding rule.
A theme is composed of a number of color families.
Common Mistakes / Misconceptions
Despite the advice that Material 2 is very very very different from Material 3, there are several reasonable mistakes and assumptions that a lot of people make.
Mistake #1: Believing the role of the primary color in Material 2 is the same as primary in Material 3.
In Material 3, the primary color impacts more than just its own color family. Surface colors that may appear to be solely gray and black tones are actually tinted with the primary color. The circled roles and palettes are affected by primary. Secondary and Tertiary colors are also derived from the primary’s position in the HCT color space but the impact is more limited as it is more common to change them. It also bears noting that the key colors for neutral and neutral variant can be changed as well however it might be less obvious to do so.
Mistake #2: Using your brand color as the primary color.
Because so much is derived from primary, using a bold color for primary will make your theme awash in that color. That’s a big problem if your design system wants you to build from white.
Mistake #3: Having a color system half in Material and half outside it.
It’s pretty common to need more colors than what Material provides. These often come in pairs that might align in function with color families. In the best case, you may have parts of your app that have inconsistent color or contrast. In the worst case, content may become illegible if the container colors shift too much based on user preferences.
A common mistake is for a developer to manually change say a surface color or background of a component without taking the onSurface \ on<ColorRole> color into account.
I’ve also seen third-party implementations of Material themes that often seize on certain aspects of the system and ignoring others. I’ve seen my fill of "normal theme but adds pastel colors" takes on Material.
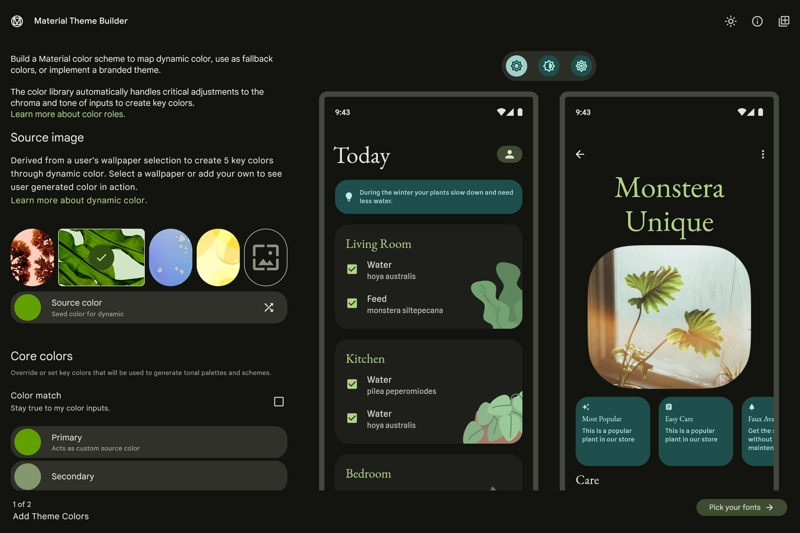
Tooling
The added complexity to create a theme is lessened somewhat by Material Theme Builder. It helps you create theming code in Android Views, Compose, Flutter, and Web. It’s coming to its third anniversary. Use it.
Future considerations
There are a couple things that aren’t on folks' radars that I think should be, namely color match, contrast, and extended color. If you are just now coming to Material 3, I’d encourage looking into them from day 1.
Color Match
In brief, color match slots a color very close to your input color into a theme versus shifting it as the default algorithm does. There are additional implications like what to do in dark mode but the "I put in black and it made it red or blue" problem can be mitigated.
The feature was released in the sort of quiet zone just before the holidays last year so don’t feel bad if you didn’t hear about it. I’ll be discussing it in detail in a future post.
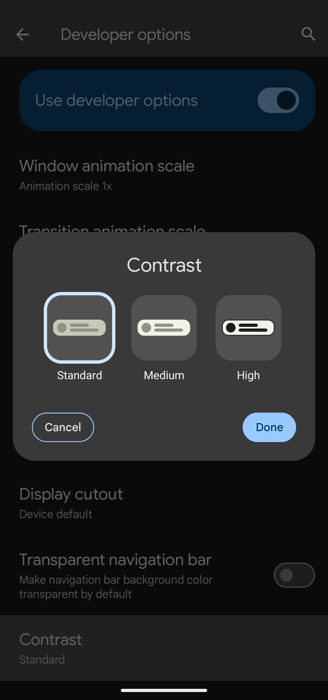
Consider Adopting Contrast
Android 15 will have a contrast control. It’s currently in Developer Options, final location and UX to be determined. The user will be able to select between three levels of contrast: standard, medium, and high. Current themes will slot into standard.
If you are using dynamic color, the shifts in contrast will take place automatically at the system level. You will have to handle any custom/static themes and colors on your own. The current version of Material Theme Builder does export theming code for light and dark for all contrast modes.
I’ve updated Reply in android/compose-samples with helper code to demonstrate selecting the proper colors for a given contrast level.
Consider Using Extended Color
Extended color is a part of the Material spec that gives you a place to create additional color families to include with your theme. Material Theme Builder will make sure these colors align to the spec and package them up, leaving the last mile of implementation to you (likely a CompositionLocal on Compose or a ThemeExtension on Flutter).
This is one of those things that is easier to digest with an example so stay tuned.
Hopefully after reading this, you have a bit more insight into how Material 3 works and no longer see it as a wall of random colors.
Dreamland Japan by Frederik L. Schodt is not a new book, having been published in 1996, but nonetheless provides a good overview of manga (and to an extent anime) from its inception to "almost" modern day.
Just like there is a genre of fiction or music for almost everyone, I believe the same could be said for manga. Unlike their American cousins that tend to be dominated by typical strongman or superhero fare targeted to young men, Japanese manga also include subgenres catering to young women, historical fiction, same sex couples and romance, slice of life, and even the seemingly mundane. I’m currently reading a culinary manga Oishinbo that has little action and is a journey through Japanese food and custom. Through the overview of genres, I learned the name for the manga I gravitate towards is called "gekiga" (dramatic pictures). It uses a more cinematic art style and is generally less whimsical and more gritty.
One of my major discoveries from the book was the work of Osamu Tezuka whose prolific outoput has inspired others to call him the Father of Mange. One of his well known works is Astro Boy and Kimba the White Lion, the later of which would be a conversation point when Disney’s The Lion King was released some 30 years later.
After my initial reading of the book, I learned that Tezuka’s style was a big fan of Disney comics specifically the work of Carl Barks, who drew epic Donald Duck comic adventures. Tezuka’s anime adaption of Astro Boy was one of the first widely aired anime in the US. His oeuvre almost seems like two different artists with the earlier being more light and Disney-esque fare and the having more gekiga themes, dark topics, and historical fiction.
It’s interesting to consider that a very Japanese art form had American inspiration and that years later, it would arrive back at America’s shores.
For more information about Carl Barks, check out this video from @mattwith4ts
Edward Oscar Heinrich was a complicated figure. On one hand, he perfected many of the techniques used in forensic science today and was such a great autodidact that he passed his state's pharmacy board exam without a high school degree. On the other hand, his reputation, built by his work on high profile cases, lent credibility to the pseudoscience handwriting analysis cases that formed a bulk of his caseload.
In a time where not only do most people not carry pens nor regularly write, it's easy to think it's absurd that you can determine someone's mood, personality or intent from their handwriting. But we still have contested science in today's forensics, in the branch of arson investigation commonly called fire science. Lots of "conventional knowledge" that's been long disproven is still presented as fact with little recourse for the accused.
Another contemporary view I had upon reading the book is how we still confer reverence on folks that have great success on an unrelated area. Being a SuperBowl winning quarterback doesn't make you an automatic expert on vaccine science. We need to be able to honor their accomplishments in one area without fast-tracking them to credibility in another where they haven't earned it.
Nonetheless, the book was an interesting time capsule into what was cutting edge 100 years ago.
It's very weird to learn that everything you were taught about the inception of Texas, its larger than life reputation, and "Don't Mess With Texas" was built upon a well-constructed lie. They say "history is written by the victors." More important is what they choose not to write. For example, the mythos of Texas omits that a lot of the conflict boils down to Mexico's displeasure with slavery in the Tejas. Also not noted is illegal immigration into Mexico with slaves (ironic in today's climate) or US intervention in the conflict.
The well sourced book also chronicled Hollywood's role in remaking the Alamo church, a site that was unimportant in the battle, into hallowed ground. The actual site of most fighting, the longhouse, was willfully destroyed in the efforts to preserve the complex because it didn't fit the funder's plans for "America's ruins."
There are many more little tidbits like this in the book. I highly recommend.
Most folks know about the marquee Google perks like the food and buses. One of my favorites that doesn't get mentioned much are educational services. Education is something you can take with you. It also goes well with my job in Developer Relations. To do this job well, I think you should be constantly learning things in and outside your field of study. The Project Management Professional Certificate is kind of work adjacent so that's an extra plus.
A way into tech without a degree
Google Career Certificates are training programs meant to give people a means to break into tech possibly without a degree. Beyond Project Management, there are certificates in Digital Marketing/E-commerce, IT Support, Data Analytics, and UX Design with other areas in development.
In addition to the career certificates themselves, Google set up an employer consortium that will factor completion of the certificates into their hiring decisions for new candidates or to use them to "reskill" their current employers.
What are the courses? How are they?
Courses:
Foundations of Project Management
Project Initiation: Starting a Successful Project
Project Planning: Putting It All Together
Project Execution: Running the Project
Agile Project Management
Capstone: Applying Project Management in the Real World
The first course starts with an overview of what a project manager does. Each of the next four courses have you working on small tasks somewhat in isolation based on a brief/stems for a sample project. The capstone course presents a totally new project for which you must work through creating all the project documents.
How much does it cost?
To complete the program, you need a Coursera subscription. Either $39 USD per month for a single professional certification or Coursera Plus that gives you access to all the programs. At the time of writing, it was $59 per month or $399 USD for a yearly subscription. Full disclosure, I paid no fee for the course as it is covered in my educational benefits. The Grow with Google team didn't see or approve this write-up before hand.
How long did it take to complete?
Grow with Google quotes about 3 to 6 months of time if one works on the credential for 10 hours per week. We tended to say the same thing at Udacity and it can be variable. We had seen folks take a year or zoom through things in under 3 months to minimize costs. I had the benefit of not paying for the content so I didn't have to rush. I took big breaks with several clear crunch times where I got a lot done. Being able to watch videos on double speed also helps. The final course revisits a lot of the concepts from the other courses so taking your time there will help you in the end. Big caveat and disclaimer that I have a lot of experience making and beta testing content like this. It was about 2 months of actual work time spread over about 15 months.
What kind of assessments are there? How many ? What are they like?
There are three types of assessments: practice quizzes, graded quizzes, and peer graded assignments. Most of the practice quizzes can skipped and don't factor into your grade until you reach the last course. It uses them as prep steps for the peer graded assignments.
There were 25 graded quizzes and 13 peer graded assignments throught the six courses. The tasks range from making project charters and stating RACI (Responsible, Accountable, Consulted, Informed) tables to planning tasks for a sprint to writing persuasive emails to stake holders to get consensus.
Was it worth it?
Yes. I have no goal to become a project manager but have found myself often in a position where I didn't have one and needed to take on some of those responsibilities to move a project forward or I had a project idea and the lack of a project manager was used as a cudgel against me. In those cases, being about to think through the project to entice a project manager to take on the project was helpful.
Beyond those wanting to break into project management, I think small dev teams could benefit from the content perhaps splitting the responsibilities among them. If this existed back when I was in college or if I knew what project management was then, I might have referred it to the folks who hit the wall in Computer Science when the curriculum ramps up in difficulty and they dropped it thinking Computer Science isn't for them. Being a developer isn't the only way to work in tech.
I've worked for an airline before...when multiple hurricanes hit Florida in a short span. I was told I was ruining their weddings/vacations/etc. People straight up lied to me when I had all the evidence to prove it and then cussed me out when I had to call out their lies. I think I've earned a small soapbox to rant about the recent events. Here are the things I think contributed to the catastrophic failure at Southwest:
Problem 1: Point to point flying.
A point to point system relies on the system being generally healthy because you have aircraft coming from wherever going to wherever. So instead of weather(WX) at origin and destination, as a passenger I have to think about WX at every other city that flight has visited before me. This makes for a bad customer experience because "why is my flight delayed or CXLD but not this flight that leaves later?" is a thing. Hub/Spoke do suffer greatly when there is bad WX at a major hub, but it's usually contained somewhat and there is a prioritization of which flights will get takeoff slots (usually international, then hub to hub).
Problem 2: Seating.
Being a decently tall dude, seat anxiety made me stay away from Southwest. The boarding group + number helps a bit but the problem for me is the fact that on Southwest, your boarding pass is a not really a guaranteed seat. They don't by policy overbook (as in intentionally sell more seats than are available) but in the case of a cancellation, reduced capacity/positive space employees, you can end up in an oversold situation (incidentally more passengers than seats). There's a nuance of difference but it's hard for the passenger to understand not unlike the difference between non-stop and direct. The point isn't to hate on open seating but it feels less like I have a guaranteed seat and more like I have a claim ticket to redeem for a seat...maybe that's just me.
Problem 3: Lack of capacity.
Back in the day, I could easily travel non-revenue to Europe with only a small worry of having to kill 4-5 hours at ATL or JFK. Capacity was tight pre-COVID and it still is. Lack of extra capacity means it's harder for the system to absorb passengers from CXLD flights.
Problem 4: Lone wolf mentality.
One little known fact is that while it is not encouraged and nigh impossible to do easily, most airlines can book segments on other airlines. This is beyond what airlines they may codeshare with. These interline agreements allow an airline to handle check-in and carriage of the passenger / baggage. Handoff of baggage usually is seamless. For boarding passes, each airline might reprint the BP in their format but that's a minor inconvenience. This is important in irregular operations(IROP) because airlines with an interline agreement have some capacity to book on other carriers that aren't affected by the same issue.
Southwest by policy doesn't interline with anyone and its capacity isn't even viewable/bookable on the major booking systems. I understand the initial allure when the internet was slow to get folks to come to your site and book. People are more savvy, price check easily and...multiple tabs are a thing.
Problem 5: Lack of tools/That cop
I could be wrong but I've never noticed banks of phones in airports for Southwest to handle changes. At DL, those were called DL Direct and it rang through to me at a higher priority than elite members. I even had more power on those calls because I was deemed to be "at the airport." It was airport, reissues, Skymiles/Elite, General Sales IIRC.
These desks are usually PAST SECURITY. The advice to exit the secure area and talk to the check-in agents endangers the other flights leaving that day because you will have folks with a departing flight mixed in with those who are canceled and it's the worst customer service to have found someone a seat but have to let it go because there is no way they'll get through security in ATL before boarding or tell someone that you gave their seat away because they were in line and not checked in because someone told 200 people to get in line ahead of them. When I "protected" a passenger on a flight because they were likely to miss their connection, the boarding pass from the previous flight still scan. If the gate agent had extra time, they would print new boarding cards for the folks, otherwise during boarding, the existing boarding card would spit out a seat assignment ticket. IE STILL VALID IANAL so don't get arrested but staying inside the secure area is in your best interest most of the time.
How does Southwest recover?
It seems like they have been living in the mindset of "if that flight is CXLD, there will be another flight in an hour or two." Climate change affects everything. If that 100 year event becomes a 5, 10, or 20 year event and it's not in your modeling, that's a problem.
I hope the company invests in the tech side. They need to start thinking about themselves as a tech company. Given the other things I didn't touch on like the FAA fines if flight crew goes over their legal limit, perhaps this multi-day shutdown of the full system was the only way to reset things. I wouldn't want to explain this to the customer when all the other airlines are fine. If you are a Southwest passenger, be nice to the agent on the phone, they are trying their hardest to help you. Your salty attitude x 80 or 100 calls is what they've been dealing with on a daily basis. Don't get yourself put in the penalty box or accidentally dropped.
For day 6, you need to help the elves with their communication system. Their devices receive a series of characters, one at a time. The start of a usable data packet is indicated by some x characters that are unique.
If you are doing this problem in Kotlin, 95% of the work can be done for you using a pre-defined function in the collections library. I, however, didn't think of it until AFTER completing both stars.
Part I and II
I used much of the same logic for both parts as the only difference was the required number of unique characters. I iterated over the string from zero to string length minus the required size. On each iteration, I created a substring for the target size and tested it for uniqueness.
package adventofcode.y2022
import adventofcode.AdventOfCode
import adventofcode.DayOf2022
import java.util.*
class Day06 : DayOf2022(6) {
var scan: Scanner
init {
//DEBUG = true
scan = if(DEBUG)
testScanner
else scanner
}
lateinit var part2Line:String
override fun part01(): Any? {
val line = scan.nextLine()
part2Line = line
for (i in 0..line.length-4) {
val x = line.substring(i..i+3).toCharArray().distinct()
if (x.size == 4) {
return i+4
}
}
return super.part01()
}
override fun part02(): Any? {
val line = part2Line
for (i in 0..line.length-14) {
val x = line.substring(i..i+13).toCharArray().distinct()
if (x.size == 14) {
return i+14
}
}
return super.part02()
}
}
fun main() = AdventOfCode.mainify(Day06())
If you are thinking that sounds a lot like windowed with the requirement for no partial windows. You are totally correct.
When I start a new problem, a lot of times I will look at the sample test data first to try and understand what I might need to do with the data. This test data for Day 5 had me perplexed for a bit.
[D]
[N] [C]
[Z] [M] [P]
1 2 3
move 1 from 2 to 1
move 3 from 1 to 3
move 2 from 2 to 1
move 1 from 1 to 2
The premise is that you are in the supply docks and have a crane moving around containers. You must move them in a prescribed order and report their final state.
Part I
After a while, I realized it was the combination of a stack/queue problem and a regular expression problem. I HATE doing regexes. Further, in the first section of the input, the last line had the ids of the stacks and I could use that index position to find all the crates in that stack. The lines were varying lengths so I needed to make sure to not throw an index error but that was easy to manage.
val stacks = mutableListOf()
while(scan.hasNextLine()) {
val line = scan.nextLine()
if (line.isEmpty()) {
break
} else {
stacks.add(line)
}
}
val lastLine = stacks[stacks.size - 1]
val stackIds = stacks[stacks.size - 1].split(" ").filter{ it.isNotEmpty()}
val indices = stackIds.map { lastLine.indexOf(""+it) }
queues = Array>(stackIds.size) {i -> ArrayDeque()}
for (i in 0..stacks.size-2) {
stackIds.forEachIndexed { j, value ->
val index = indices[j]
if (stacks[i].length > index) {
val c = stacks[i][index]
println("value c:" + c)
}
if (stacks[i].length > index && stacks[i][index] != null && stacks[i][index] != ' ') {
queues[value.toInt()-1].add(stacks[i][index])
}
}
}
The sneaky bit was the regex. My first version worked perfectly on the sample data but wasn't even close with the real data set. It turns out I made a subtle error that only became apparent when I switched datasets. My original regex only worked on single digits.
Regex("""move(\d)+ from (\d)+ to (\d)+""")
should have been
Regex("""move (\d+) from (\d+) to (\d+)""")
The parentheses define the digits as a matchable group, so putting the plus (indicating one or more items) causes the part of the input to be matched and affecting the results. With that sorted I could move the proper quantity of crates from the right source to the right destination.
fun moveObjects(queues:Array>, quantity:Int, source:Int, destination:Int) {
repeat(quantity) {
// remove from old
val valueToPop = queues[source-1].pollFirst()
// push to new
if (valueToPop != null)
queues[destination-1].addFirst(valueToPop)
}
}
Part II
In Part II, you were still moving crates but instead of one by one, you needed to move them as a set and preserve initial ordering. To do this, I opted for a double ended queue as temporary storage and added items into it using addLast. When adding to the destination, I added each item to the front of the destination with addFirst but with the source items being repeated calls to removeLast on the temporary storage location. you could have done it with another data structure like a simple array but I'll take readability over terseness and having to track multiple indices.
fun moveCrates(q:Array>, quantity: Int, source: Int, destination: Int) {
if (quantity == 1) {
moveObjects(q, 1, source, destination)
} else {
val tempQueue = ArrayDeque()
repeat(quantity) {
val valueToPop = q[source-1].pollFirst()
if (valueToPop != null)
tempQueue.addLast(valueToPop)
}
while(tempQueue.isNotEmpty()) {
q[destination-1].addFirst(tempQueue.removeLast())
}
}
}
override fun part02(): Any? {
queuesClone.forEach{println(it)}
instructions.forEach {
moveCrates(queuesClone, it.first, it.second, it.third)
}
var topCrates = ""
queuesClone.forEach {
val peek = it.peekFirst()
if (peek != null) topCrates += peek
else topCrates += " "
}
return topCrates
}